基于 Transfomer 的预训练模型 | GPT
GPT(Generative Pre-trained Transformer)是一个由 OpenAI 开发的先进的自然语言处理(NLP)模型,专门用于处理各种语言任务。它基于 Transformer 架构,一种在 NLP 领域非常有效的深度学习模型结构。GPT 模型在多种语言任务上表现出色,包括但不限于:文本生成、问答系统、机器翻译、文本摘要、感情分析等。
要注意的是,不同于 BERT,GPT 是一个自回归模型,使用了监督学习的方式,进行从左到右的语言建模,因此 GPT 在生成时只能查看之前的单词(单向上下文)。
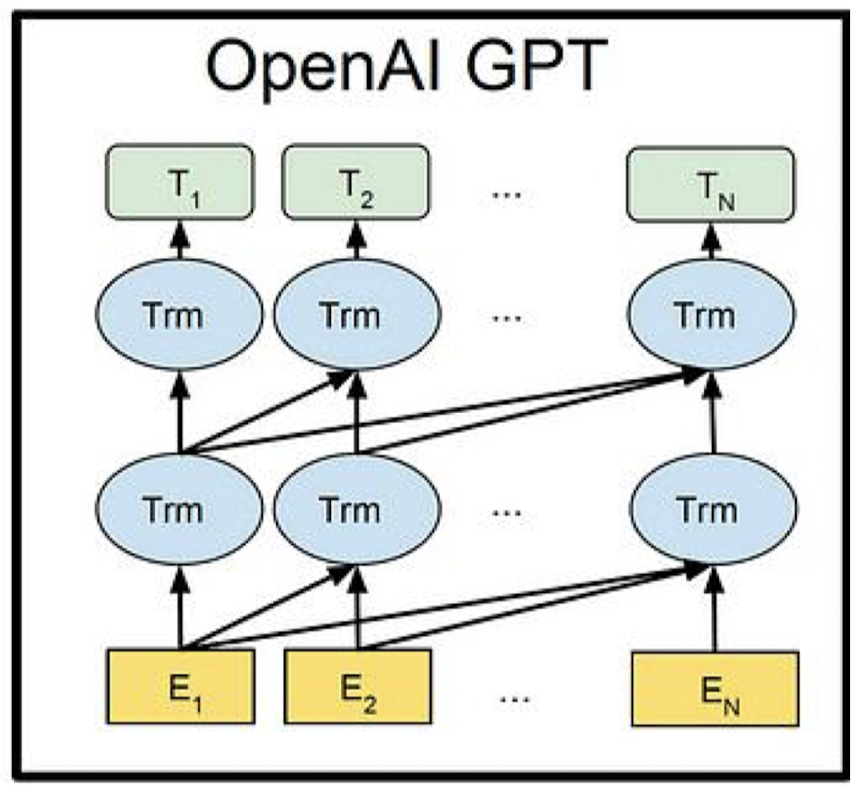
基本结构
由于 GPT 任务的特殊性,其只保留了 Transformer 的解码器(Decoder),舍弃了编码器(Encoder)。所以如果能够理解 Transformer,那么理解 GPT 模型自然也就不难了。
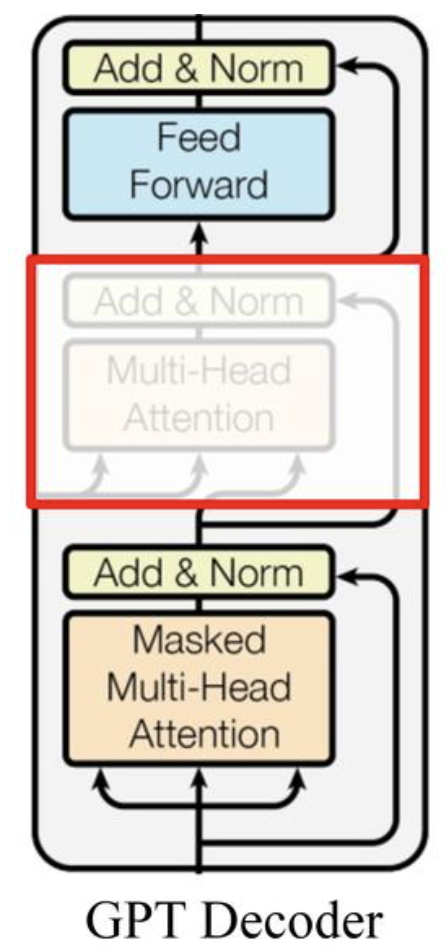
Decoder 层面的自注意力机制允许模型在生成每个新词时看到之前的所有词,这对于生成连贯的文本至关重要。而 Encoder 部分是为了编码输入序列到一个固定长度的连续表征中,这在 GPT 的预训练目标中并不是必要的。此外,省略 Encoder 可以简化模型的结构,并专注于提高文本生成能力。
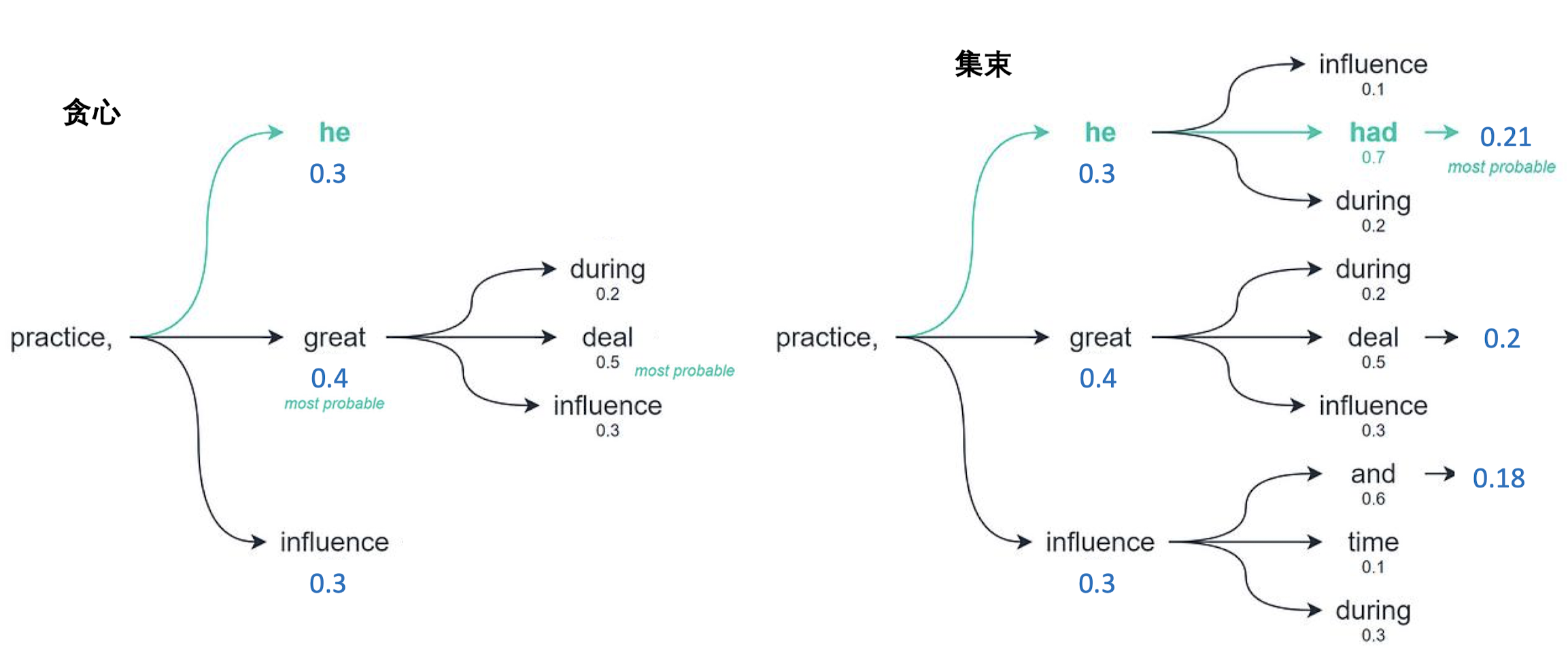
两种文本生成策略
- 贪心解码:
- 在每一步,模型选择概率最高的单词作为下一个单词。
- 这种方法速度快,计算成本低,但可能不是最佳选择,因为它不考虑整体句子的最佳组合,可能导致局部最优解。
- 集束搜索解码:
- 在每一步保持多个可能的候选序列(称为 “集束” 或 “beam”)。
- 集束的宽度(Beam width)决定了在每一步有多少候选序列被考虑。
- 集束搜索会在每个时间步骤考虑多个可能的继承候选,并在序列结束时选择整体得分最高的序列。
- 这种方法更能找到质量高的序列,但计算成本更高,速度也较慢。
代码实现
GPT Decoder
1 | |
文本生成
1 | |
GPT 完整实现
1 | |
预训练一个轻量 GPT
定义语料库类
1 | |
训练类
1 | |
训练过程
1 | |
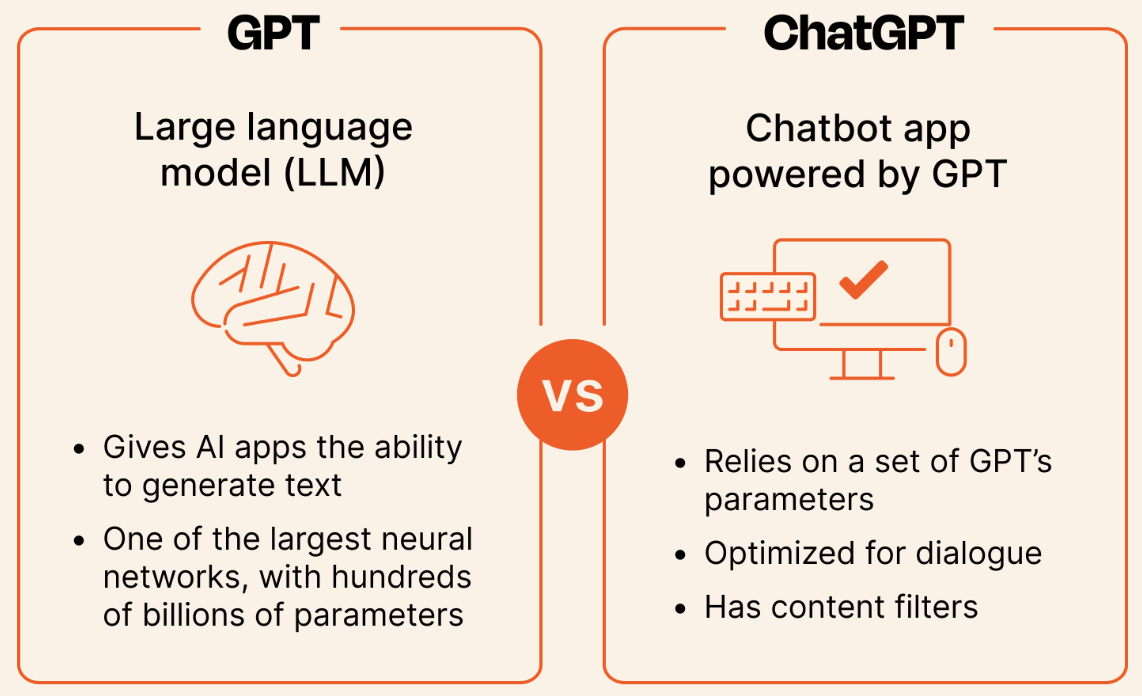
从 GPT 到 ChatGPT
GPT 预训练模型是完整语言模型的基础。预训练模型通过在大量文本上学习语言的统计规律,来获得对语言的一般理解。这个阶段模型不专注于任何特定任务,只是学习如何预测文本中下一个单词的出现。
完成预训练后,模型可以用于各种特定的语言任务,如文本生成、翻译、问答等。为了在这些任务上表现得更好,模型通常会进行微调(Fine-tuning),在特定任务的数据集上进一步训练,以适应特定的语言使用场景。预训练模型为这个过程提供了一个强大的起点,微调则根据特定任务进一步优化模型。

基于 Transfomer 的预训练模型 | GPT
https://goer17.github.io/2023/12/03/Transfomer-家族之-GPT/