循环神经网络 RNN
时序神经网络
时序神经网络(Time Series Neural Networks, TSNN)并不是一个特定的神经网络类型,而是指那些用于处理时间序列数据的神经网络。这种数据具有时间顺序的特点,如自然语言、股票价格、气象数据、音频信号、视频帧等。常见的时序神经网络有 RNN、LSTM、GRU、1D CNN 等等。
设想接下来一个场景:我们设计了一个自动购票系统,我们根据用户输入的语句自动判断其起点、终点以及出发时间。
Input:
- I wish to go to Changsha from Beijing on December 12th
Output:
- Time:12.12
- From:Beijing
- To:Changsha
在该系统中,用户的输入被认为是具有时序性的,即 3 个关键词通过不同的组合或使用句势语法结构可能影响到输出的结果。
因此,我们需要一个能够处理时序信息的神经网络。
RNN
循环神经网络(Recurrent Neural Networks, RNN),也叫递归神经网络,它的关键思想是利用网络的循环链接来储存之前时间步的信息。
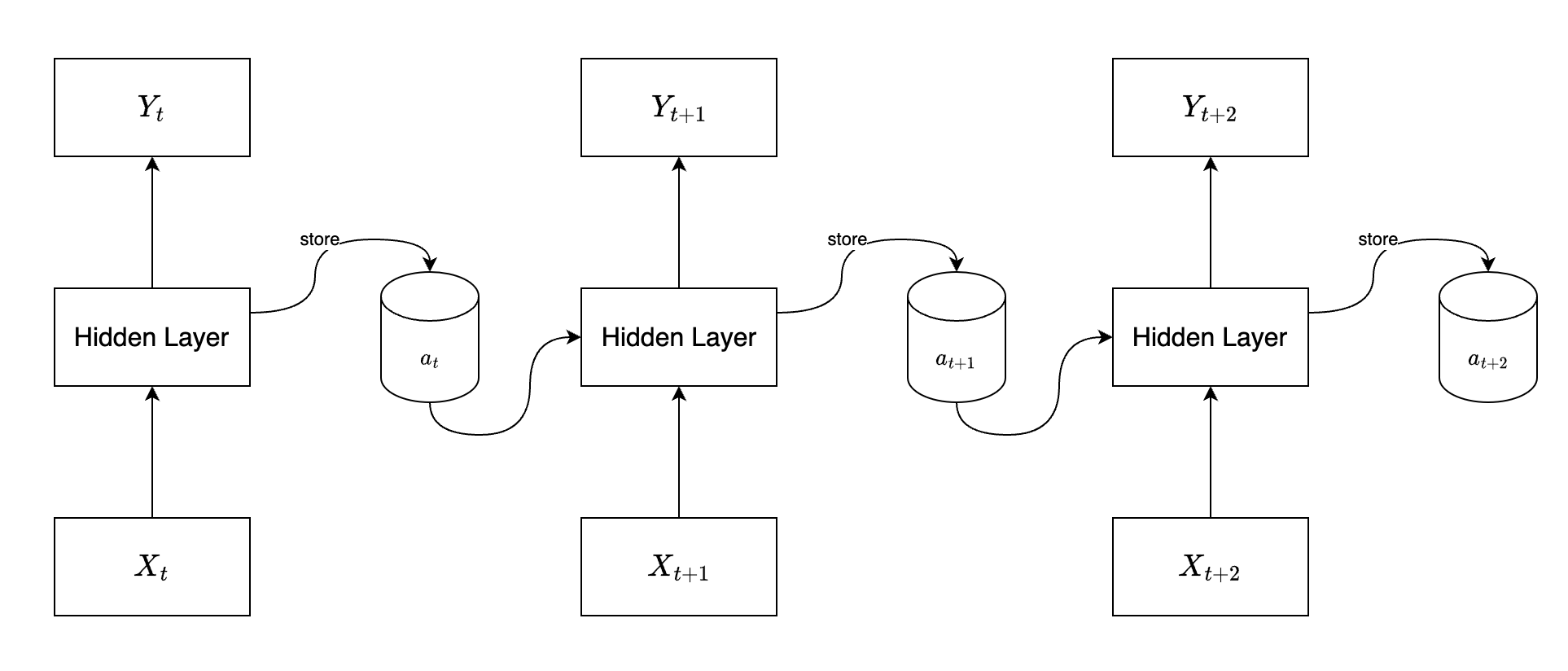
在 RNN 中,会有一个记忆单元,每次存储上一次隐藏层的输出,然后在下一次输入时使用该记忆单元中的向量。
其更新方式通常为: \[ a_t = \sigma(W_{xa} x_t + W_{aa} a_{t - 1} + b_a) \] 其中,\(x_t\) 是时间步 \(t\) 的输入,\(a_{t - 1}\) 是上一个时间步的隐藏状态,\(W_{xa}\)、\(W_{aa}\) 表示权重矩阵,\(b_a\) 表示一个偏置,\(\sigma\) 在这里是一个激活函数。
RNN 神经网络早期有两种主要形式,分别是 Elman 神经网络和 Jordan 神经网络,这两种网络在 90 年代初由 Jeffrey Elman 和 Michael I. Jordan 分别提出。
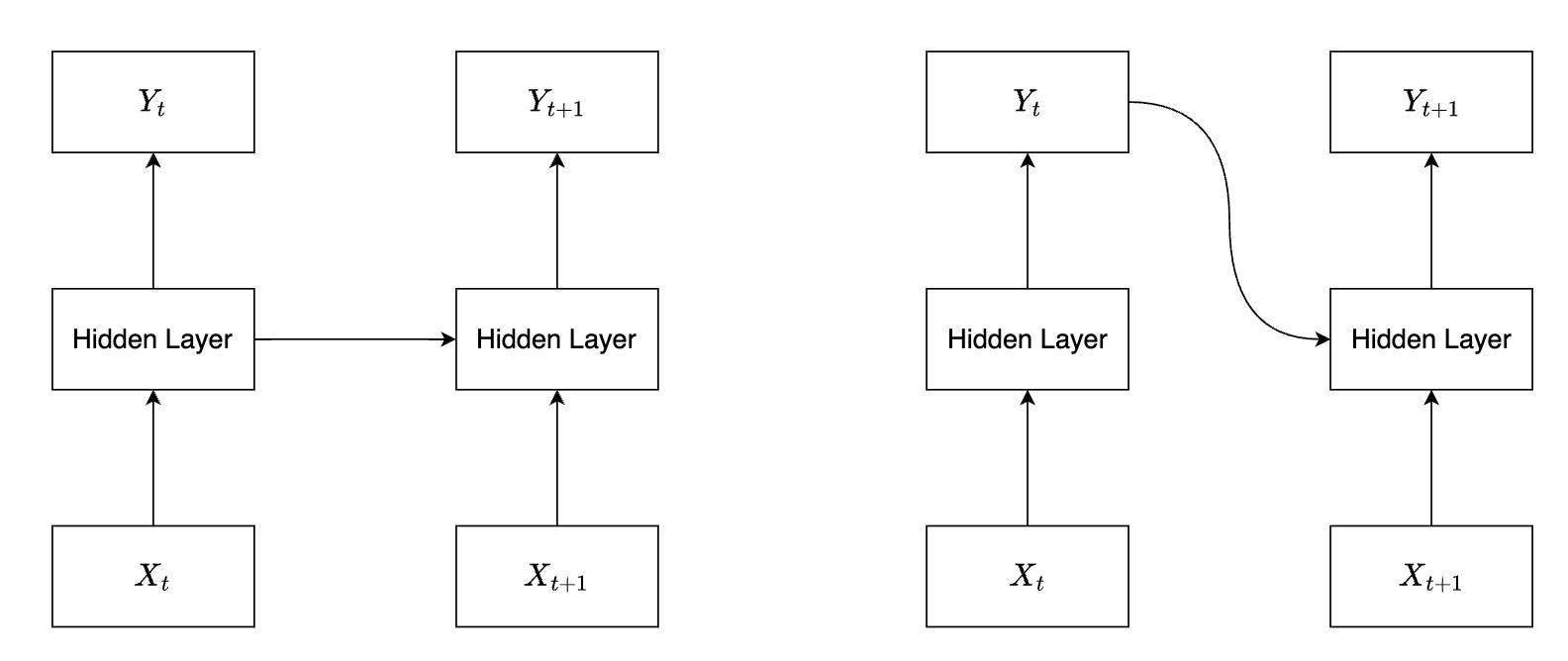
- Elman 网络是一种三层网络,包括输入层、隐藏层和输出层。其特点是隐藏层的输出(即隐藏状态)被反馈到一个特殊的上下文单元,然后在下一个时间步,这些上下文单元作为额外的输入供给隐藏层。
- Jordan 网络与 Elman 网络非常相似,但它们的循环连接方式有所不同。在 Jordan 网络中,输出层的值被反馈到上下文单元,然后这些上下文单元作为额外的输入提供给隐藏层。
BPTT
BPTT(Backpropagation Through Time)是一种特殊的反向传播算法,用于训练时间序列数据上的循环神经网络(RNN)。由于 RNN 的特殊结构,标准的反向传播算法不能直接应用于它们。BPTT 是对反向传播的一个扩展,使其适用于处理 RNN 的时间依赖性。
接下来我们举一个具体的例子,来说说 BPTT 是如何计算的。
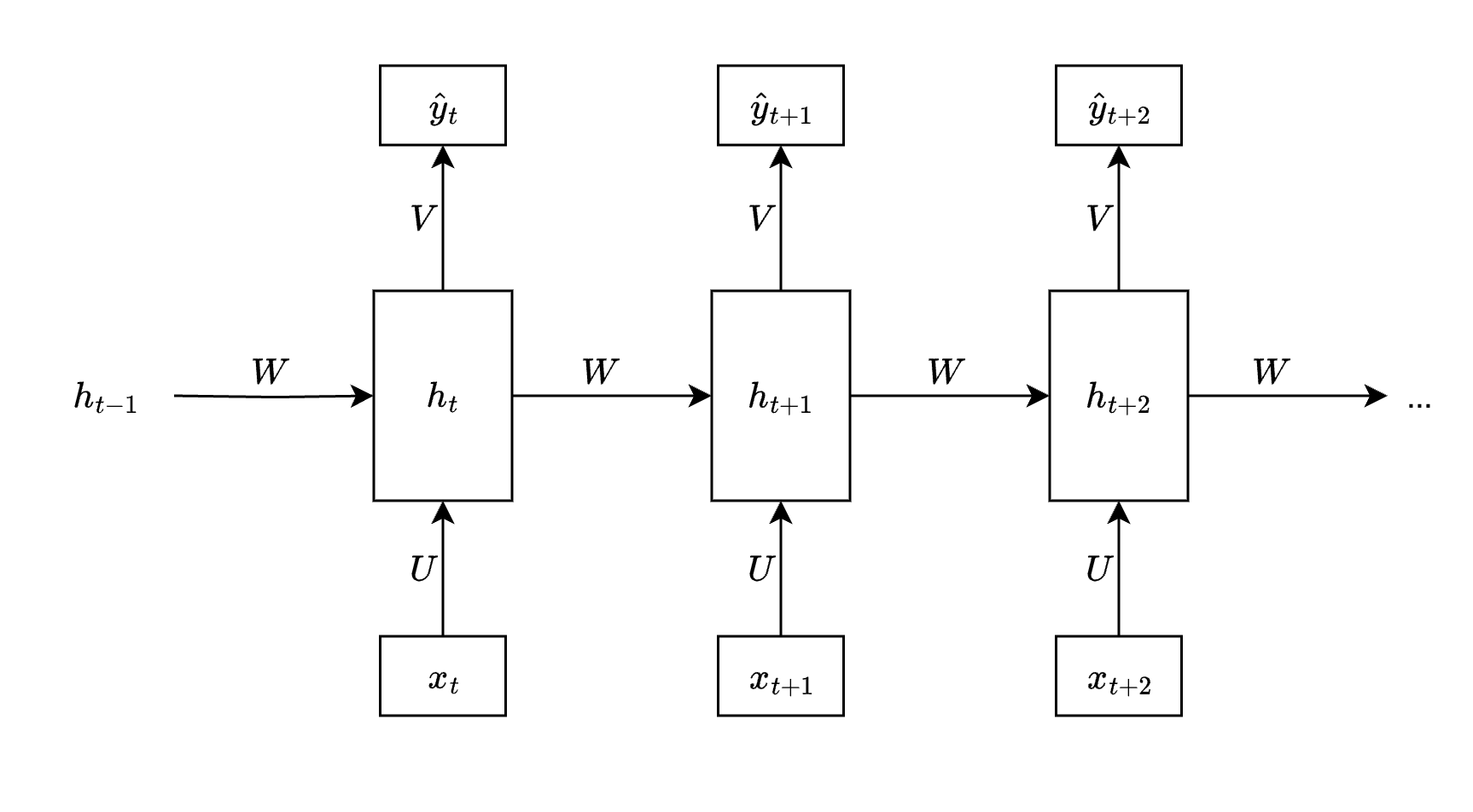
假设在上述 RNN 网络中,输入层、输出层、隐藏层和参数矩阵 \(U\)、\(W\)、\(V\) 的大小定义如下: \[ \begin{array}{} x_t \in R ^ n \\ h_t \in R ^ d \\ \hat y_t \in R ^ k \\ U \in R ^ {n \times d} \\ V \in R ^ {d \times k} \\ W \in R ^ {d \times d} \end{array} \] 其中: \[ \begin{array}{} h_t = \delta(x_t U + h_{t - 1} W + b_W) \\ \hat y_t = \delta(h_t V + b_V) \end{array} \] \(\delta(\cdot)\) 在这里是激活函数。
假设损失函数是 \(f(\hat y_t, y_t)\),则我们可以认为到 \(T\) 时刻为止,总损失值 \(L = \frac{\sum_{t = 0} ^ T L_t}{T + 1} =\frac{\sum_{t = 0} ^ T f(\hat y_t, y_t)}{T + 1}\)。
在上图中可学习参数一共有 5 个:\(U\)、\(W\)、\(V\)、\(b_W\) 和 \(b_V\)。
其中,\(V\) 和 \(b_V\) 的梯度计算与经典的梯度下降算法没有什么区别,其只在输出层使用,不参与隐藏层的计算。
而对于 \(U\)、\(W\) 和 \(b_W\) 而言,其梯度的计算则会复杂很多。这里我们以 \(\nabla_{W} L_t\) 为例,来介绍 BPTT 的具体计算过程:
根据 RNN 网络的计算规则,我们可以得到隐藏层和输出层的计算图:
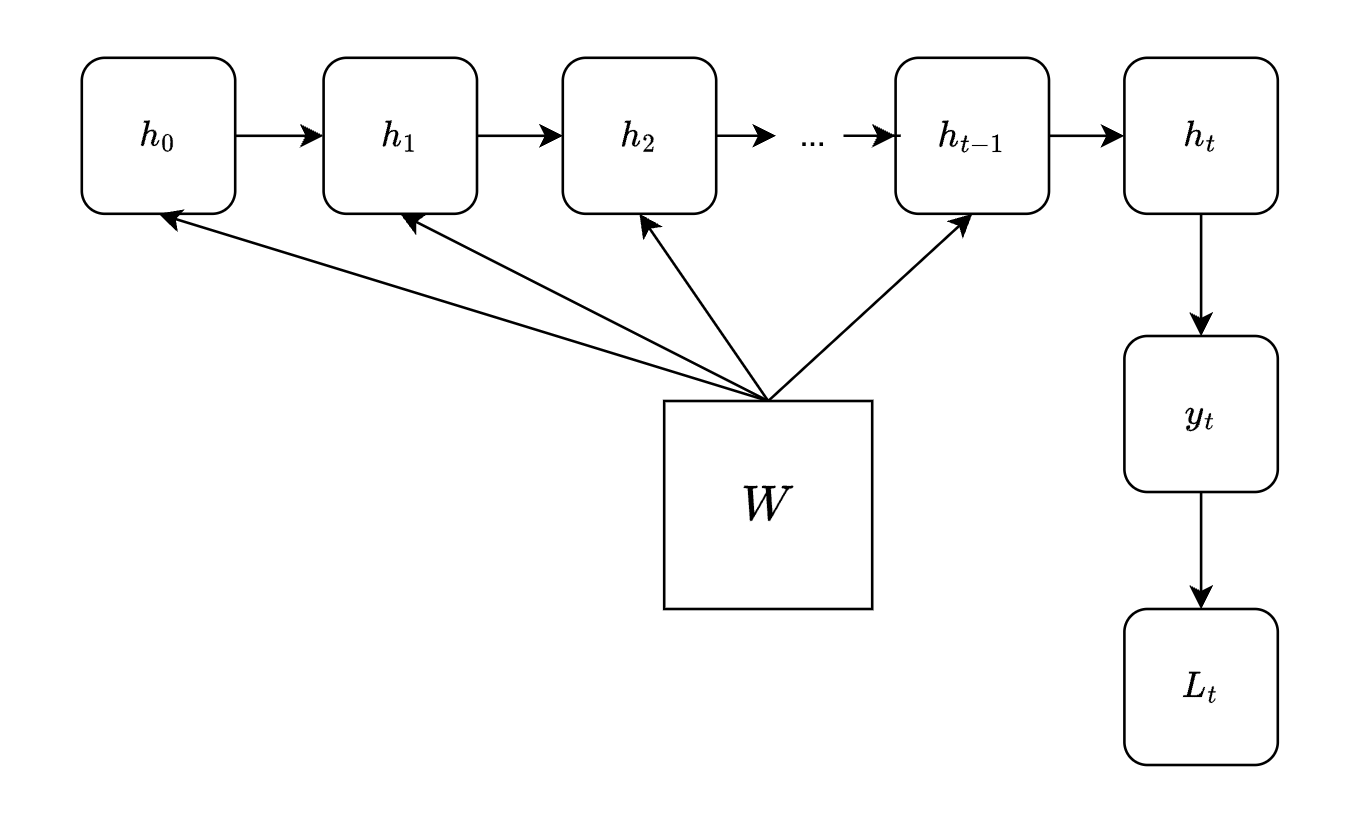
根据链式法则,\(L_t\) 关于 \(W\) 的偏导等于计算图上所有 \(W\) 到 \(L_t\) 的路径偏导之和: \[ \nabla_W L_t = \frac{\partial L_t}{\partial y_t} \frac{\partial y_t}{\partial h_t} \sum_{k = 0} ^ {t - 1} \frac{\partial h_k}{\partial W} \prod_{i = k} ^ {t - 1} \frac{\partial h_{i + 1}}{\partial h_i} \] 由此可见,BPTT 的计算中会引入大量的矩阵连乘,这使得传统 RNN 在长距离依赖序列的梯度计算上容易出现梯度消失和梯度爆炸的问题。
传统 RNN 面临的问题
- 梯度消失(Vanishing Gradients)
- 描述:当神经网络反向传播过程中的梯度值变得非常小,以至于权重几乎不更新,这种情况被称为梯度消失。
- 原因:主要因为链式法则和非线性激活函数。例如,当使用 sigmoid 或 tanh 激活函数时,如果输入值过大或过小,其导数会趋近于 0,多层网络中这种小导数的连乘会导致整体的梯度非常小。
- 结果:深度神经网络的低层(接近输入层的层)权重更新非常缓慢,导致训练过程停滞。
- 梯度爆炸(Exploding Gradients)
- 描述:神经网络反向传播过程中的梯度值变得非常大,使权重更新过大,这种情况被称为梯度爆炸。
- 原因:与梯度消失类似,梯度爆炸也与链式法则有关。但在这种情况下,网络中的梯度值大于 1,多层网络中这些大梯度值的连乘导致整体的梯度变得非常大。
- 结果:权重更新过大,可能导致网络不稳定,损失函数值震荡或发散。
- 解决方案:常见的解决方案有梯度裁剪(Gradient Clipping),即给反向传递的梯度设定一个阈值 \(M\),若梯度的模长超过了该阈值,则减小梯度到合适大小的值。
不难发现:上述提及的梯度消失和梯度爆炸都是由一个原因导致的,那就是传统 RNN 神经网络中,如果时间序列过长,可能造成隐藏层中大梯度值的连乘,指数级的增长或衰减很可能造成梯度爆炸或梯度消失。
代码实现
PyTorch 提供了 nn.RNN
模块,用于构建循环神经网络(RNN)。
示例:
1 | |
主要参数
nn.RNN 的主要参数包括:
input_size:输入特征的维度。hidden_size:隐藏层的维度,即隐藏状态的大小。num_layers:RNN 的层数,默认为1。nonlinearity:激活函数的类型,可以是'tanh'或'relu',默认是'tanh'。batch_first:如果为True,则输入和输出的张量的形状为(batch, seq, feature),默认为False,即(seq, batch, feature)。dropout:如果不为零,则在除最后一层外的每层后添加一个Dropout层。bidirectional:如果为True,则使用双向 RNN,默认为False。