数据库规范化理论
什么是数据库规范化?
数据库规范化(Normalization)是一种数据库设计技术,其旨在实现以下两个主要目标:
- 减少数据冗余(Redundancy)。
- 确保数据的依赖性是有意义的,即数据存储是有逻辑的。
函数依赖
基本定义
函数依赖(Functional Dependncy)是规范化中的重要概念,简而言之,函数依赖用于描述属性(Attributes)之间的关系。
概念:
若 \(A\) 和 \(B\) 是关系模式 \(R\) 中的两个属性集合,对于给定的 \(A\) 值,都有唯一的 \(B\) 值与其对应,我们就称 \(A\) 函数决定 \(B\),\(B\) 函数依赖于 \(A\),记作:\(A \to B\),其中 \(A\) 称为决定因子(Determinant)
若 \(A\) 和 \(B\) 相互依赖,即二者一一对应,则记为:\(A\) \(\leftrightarrow B\)
例如:
在一个学生信息的关系模型 \(Student(\underline{s\_id}, name, gender, age)\) 中,我们假设学号 \(s\_id\) 是关系模型中的主键,则有: \[ s\_id \to name \] 即:唯一的学号对应唯一的姓名,因此姓名在这里是函数依赖于学号的。
平凡函数依赖和非平凡函数依赖
我们从决定因子和被决定因子的集合关系角度出发可以将函数依赖分为两类:
平凡函数依赖(Trivial Functional Dependency):
若 \(A \to B\) ,且 \(B \subseteq A\) ,则称该依赖为平凡依赖。
非平凡函数依赖(Nontrivial Functional Dependency):
若 \(A \to B\) ,且 \(B \not\subseteq A\) ,则称该依赖为非平凡依赖。
部分函数依赖和完全函数依赖
同时,我们从决定因子属性的必要性又可以将函数依赖分为两类:
部分函数依赖(Partial Functional Dependency):
若 \(A \to B\) ,且存在 \(A\) 的真子集 \(X\) ,使得 \(X \to B\) ,我们就称 \(B\) 部分函数依赖于 \(A\) 。
完全函数依赖(Full Functional Dependency):
若 \(A \to B\) ,且不存在 \(A\) 的真子集 \(X\) ,使得 \(X \to B\),我们就称 \(B\) 完全函数依赖于 \(A\) 。
即 \(A\) 中删去任意一个属性都无法满足 \(A \to B\) 。
例如,在上述例子中,显然有 \((s\_id, name) \to gender\), 但其决定因子的一个真子集 \(s\_id\) 也满足被 \(gender\) 函数依赖,因此该函数依赖是一个部分函数依赖。相反,\(s\_id \to gender\) 就是一个完全函数依赖。
注意到,一般只有在 \(A\) 是多个特征的集合时才会考虑此分类,若 \(A\) 为单属性,且 \(A \to B\) ,则一定构成完全函数依赖。
传递函数依赖
函数依赖具有传递性,传递函数依赖(Transitive Functional Dependency)描述如下:
若 \(A\) ,\(B\) ,\(C\) 是关系模型 \(R\) 中的三个特征集合,且满足:
- \(A \to B\) 且 \(B \not\to A\)
- \(B \to C\)
则称 \(C\) 通过 \(B\) 函数依赖于 \(A\) 。
多值依赖
设 \(R(U)\) 是属性集 \(U\) 上的一个关系模式。\(X\)、\(Y\)、\(Z\) 是 \(U\) 的子集,若对 \(U\) 的任意一对关系而言,给定一对 \((X, Z)\) 的值,都有若干组 \(Y\) 值与之对应,而 \(Y\) 的取值仅仅与 \(X\) 相关而与 \(Z\) 无关,这就是多值依赖(Multi-valued Dependency)。记作:\(X \to\!\!\!\to Y\)。
我们也可以这样描述:给定 \(X\) 的值,有多组 \((Y, Z)\) 的值与之对应,且 \(Y\) 与 \(Z\) 的取值相互独立。
例如:
我们给定关系 \(subject(subject\_name, teacher, text\_book)\) 来描述学科、老师和学科教材的关系,在该关系模型中,一门学科对应多组老师和教材,而老师和教材又是相互独立的,即老师和学科教材分别只决定于学科,所以我们有: \[ \begin{array}{} subject\_name \to\!\!\!\to teacher \\ subject\_name \to\!\!\!\to text\_book \end{array} \]
平凡多值依赖和非平凡多值依赖
进一步,我们又可以将多值依赖分为平凡多值依赖和非平凡多值依赖:
平凡多值依赖(Trivial Multi-valued Dependency):
在关系模型 \(R\) 的属性集为 \(U\),属性 \(A\) 和 \(B\) 满足 \(A \to\!\!\!\to B\) 且满足以下两个条件之一:
- \(A \subseteq B\)
- \(A \cup B = R\)
我们就称该多值依赖是平凡的。
非平凡多值依赖(Nontrivial Multi-valued Dependency):
若 \(A \to\!\!\!\to B\) 且不满足以上任意一个条件,我们就称该多值依赖是非平凡的。
范式
范式(Normal Form),简称 NF,是一种数据库规范化评级标准,范式越高,数据模型越规范。
数据库规范化技术,就是不断提高数据模型的范式等级。
UNF
UNF(Unormalized Form),即无范式,是一种未规范化的表格,表格中的数据可能包括一个或多个值。
示例:
1NF
1NF(First Normal Form),即第一范式。指在一张表格中给定行和列,对应唯一的数据,且一个关系模型中的所有的属性都是不可分的基本数据项。1NF 是关系型数据库的基本要求。
示例:
UNF \(\to\) 1NF
将缺省单元格的数据进行拷贝,然后对无范式表格重新划分,即可得到每个单元格仅有一个值的第一范式表格。
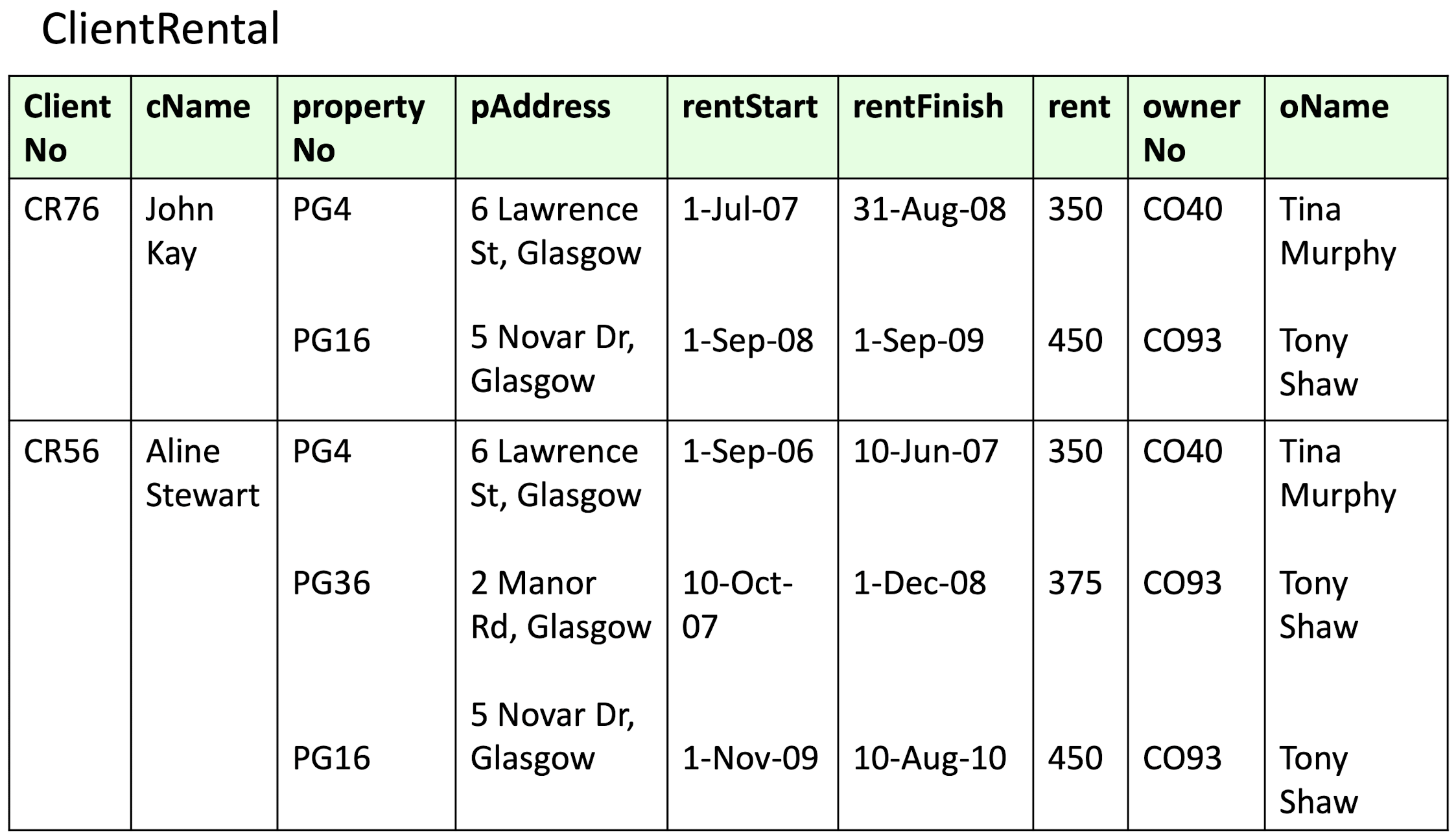
2NF
2NF(Second Normal Form),即第二范式。指在 1NF 的基础上,满足所有非主属性完全依赖于候选键(Candidate key)。
1NF \(\to\) 2NF
- 确定主键:确定 1NF 关系中的主键
- 确定函数依赖:分析非主键列对主键的完全依赖关系。也就是说,找出哪些非主键列的值是由主键决定的,而不是由主键的一部分决定的
- 创建新表:对于那些非主键列存在部分依赖的情况,将其分离出来,创建一个新的表
- 调整关系:在新的表中,将非主键列和相应的主键列作为新表的列
示例:
上述关系中存在如下函数依赖:

不难发现,我们可以指定 \((clinetNo, PropertyNo)\) 作为该关系中的主键,而函数依赖 fd2 和 fd3 的决定因子是主键的真子集,因此其被决定因子(图中下画线部分的属性)是部分依赖于主键的,因此我们要将其从当前关系中抽离出来:
最终建立的关系模型的 Schema 如下:

该关系模型的三张表都不存在非主属性对主键的部分依赖,各自满足第二范式。
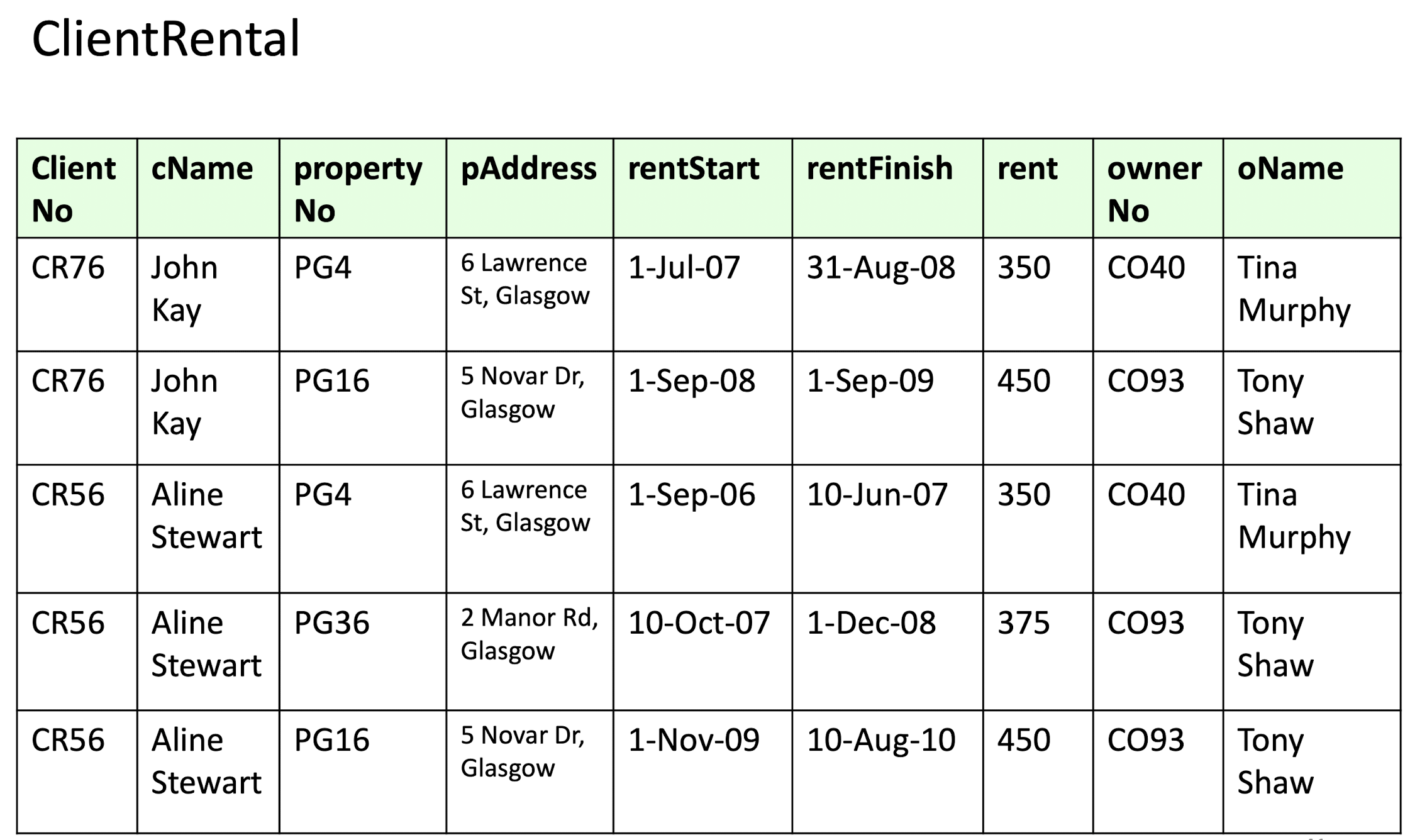
3NF
3NF(Third Normal Form),即第三范式。指在 2NF 的基础上,不存在非主属性传递依赖于候选键。
2NF \(\to\) 3NF
- 确定主键
- 确定函数依赖
- 找到依赖于主键的传递函数依赖,并将其分离出来
示例:
在上述建立的 2NF 关系模型中的第二张表 \(PropertyOwner\) 中,存在函数依赖关系 \(propertyNo \to ownerNo\)(\(ownerNo \not\to propertyNo\))和 $ ownerNo oName$ ,因此 \(oName\) 传递依赖于主键,所以我们要将其从当前关系中分离出来。
满足 3NF 的关系模型 Schema 如下所示:

该关系模型中的 4 张表都不存在非主属性对主键的传递依赖,各自满足第三范式。
BCNF
BCNF(Boyce-Codd Normal Form),即巴斯-科德范式。指在 3NF 的基础上,清除了主属性对候选键的部分函数依赖。
即满足 BCNF 的充要条件是关系模型中所有函数依赖的决定因子都是候选键。
3NF \(\to\) BCNF
- 确定主键和主属性
- 确定函数依赖
- 消除主属性对候选键的部分函数依赖
例如,有如下关系模型: \[ studentGrade(\underline{class\_id}, \underline{s\_id}, t\_id, grade) \] 该关系模型用于储存学生某门课程的成绩,每门课有且仅有一名老师来教学,可以作为该表的候选键有 \((class\_id, s\_id)\) 或者 \((t\_id, s\_id)\) ,我们选取前者作为主键,那么此关系模型中唯一的非主属性就是 \(grade\) 。
该关系模型符合 3NF,但是我们不难发现,主属性 \(t\_id\) 对主键构成部分依赖关系,因此该关系模型不符合 BCNF,因此我们将其拆分为两张表: \[ \begin{array}{} teacher(\underline{class\_id}, t\_id) \\ studentGrade(\underline{class\_id}, \underline{s\_id}, grade) \end{array} \] 这样,我们就消除了主属性对候选键的部分依赖,上述两张表各自符合 BCNF。
4 NF
4 NF(Forth Normal Form),即第四范式,即在 BCNF 的基础上,消除了所有决定因子不为候选键的非平凡多值依赖。换言之,满足 4NF 的充要条件是对于关系 \(R\) 中的每一对非平凡多值依赖 \(A \to\!\!\!\to B\) 而言,\(A\) 都是关系中的候选键。
BCNF \(\to\) 4NF
- 确定主键和候选键
- 确定关系中的非平凡多值依赖
- 消除所有决定因子不为候选键的非平凡多值依赖
例如,现有如下关系:
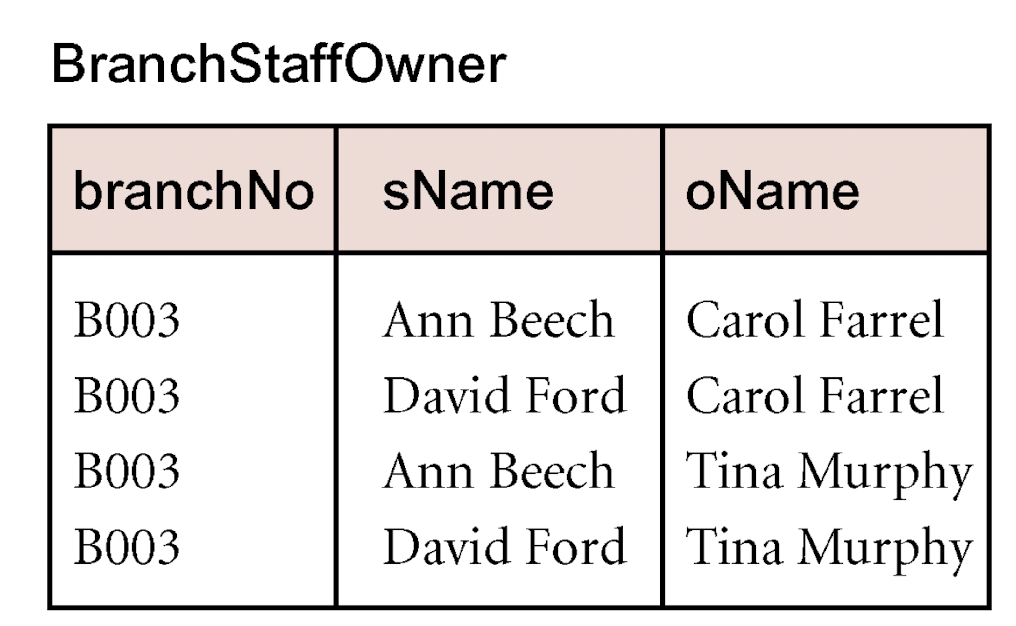
在如上 \(BranchStaffOwner(branchNo, sName, oName)\) 关系中,一个 \(branchNo\) 可以对应多组 \((sName, oName)\) ,而 \(sName\) 和 \(oName\) 之间相互不影响,所以我们有: \[ \begin{array}{} branchNo \to\!\!\!\to sName \\ branchNo \to\!\!\!\to oName \end{array} \] 而 \(branchNo\) 在这里不是候选键,所以我们要消除消除这两对非平凡多值依赖,因此将该关系拆分为两张表:
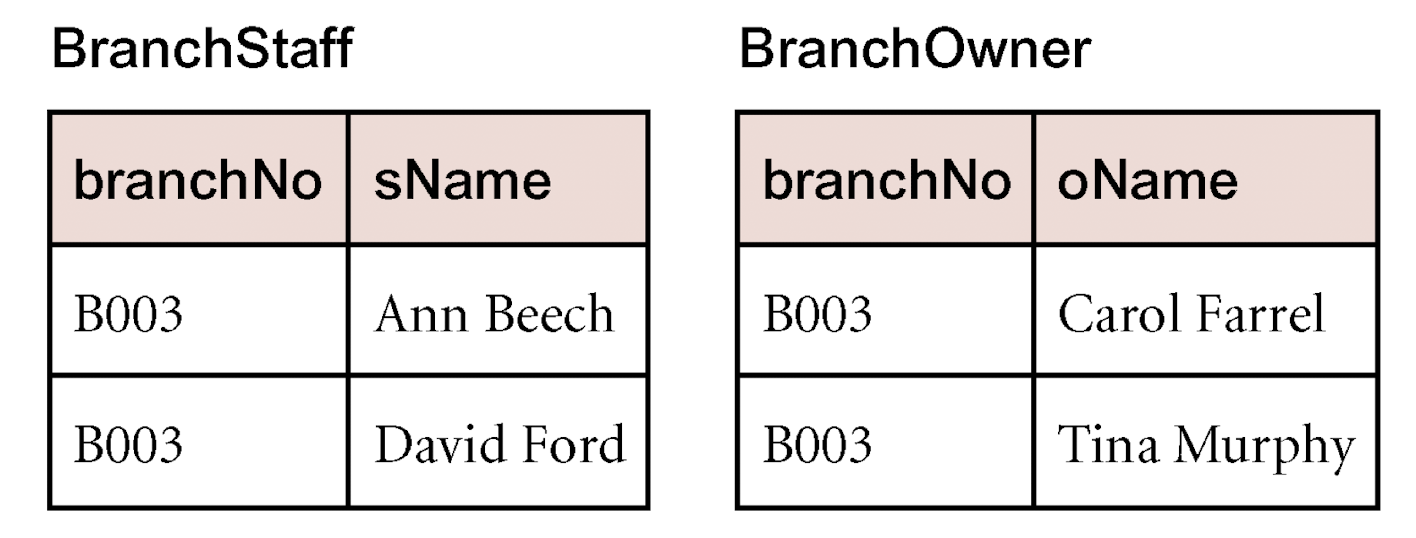
这样我们就消除了上面提到的两对非平凡多值依赖,以上两张表 \(Branch(branchNo, sName)\)、\(BranchOwner(BranchNo, oName)\) 分别满足第四范式。
事实上第四范式之上还有第五范式(Fifth Normal Form),但第四范式已经是相当规范的等级了,因此第五范式笔者在此就不赘述了。😃